
构建智能体不仅仅是“调用API”,而是需要将检索、语音、安全和推理组件整合在一起,使其像一个统一并互相协同的系统一样运行。每一层都有自己的接口、延迟限制和集成挑战,一旦跨过简单的原型就会开始感受到这些挑战。
在本教程中,您将学习如何使用2026年CES发布的最新NVIDIANemotron语音、RAG、安全和推理模型,去构建一个带有护栏的语音驱动RAG智能体。最终您将拥有具备如下功能的一个智能体:
听取语音输入
使用多模态RAG将智能体锚定在您的数据之上
长上下文推理
在响应之前应用护栏规则
以音频的形式返回安全答案
您可以在本地GPU上进行开发,然后将相同的代码部署到可扩展的NVIDIA环境中,无论是托管的GPU服务、按需云工作区,还是生产就绪的API运行时,都无需更改工作流。
先决条件
在开始这次教程之前,您需要:
用于云托管推理模型的NVIDIA API密钥(免费获取)
本地部署需要:
约20GB的磁盘空间
至少24GB显存的NVIDIA GPU
支持Bash的操作系统(Ubuntu、macOS或Windows Subsystem for Linux)
Python 3.10+环境
一小时的空闲时间
您将构建的内容
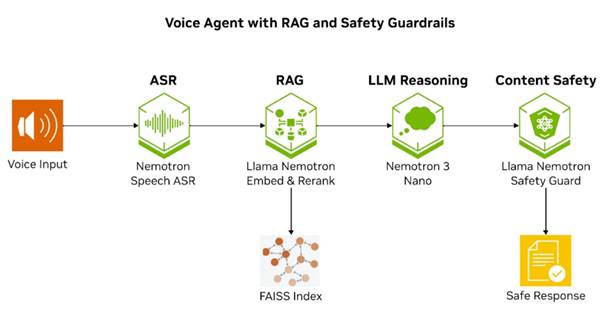
图1.带有RAG和安全护栏的语音智能体的端到端工作流。
| 组件 | 模型 | 目的 |
| ASR | nemotron-speech-streaming-en-0.6b | 超低延迟语音输入 |
| 嵌入 | llama-nemotron-embed-vl-1b-v2 | 文本和图像的语义搜索 |
| 重排序 | llama-nemotron-rerank-vl-1b-v2 | 将检索准确率提高6-7% |
| 安全 | llama-3.1-nemotron-safety-guard-8b-v3 | 多语言内容审核 |
| 视觉语言 | nemotron-nano-12b-v2-vl | 根据上下文描述图像 |
| 推理 | nemotron-3-nano-30b-a3b | 1M token高效推理 |
表1.本教程中用于构建语音智能体的Nemotron模型概览,包括用于ASR、嵌入、重排序、视觉语言、长上下文推理和内容安全的模型。
步骤1:设置环境
要构建语音智能体,您需要同时运行多个NVIDIANemotron模型(如上所示)。语音、嵌入、重排序和安全模型通过Transformer和NVIDIA NeMo在本地运行,推理模型则使用NVIDIA API。
uvsync--all-extras
配套的Notebook会处理所有的环境配置。设置用于云托管推理模型的NVIDIA API密钥,即可开始使用。
步骤2:使用多模态RAG构建智能体基座
检索是可靠智能体的支柱。借助全新的LlamaNemotron多模态嵌入和重排序模型,您可以嵌入文本、图像(包括扫描文档),并直接将其存储在向量索引中,无需额外的预处理。这可以检索推理模型所依赖的真实上下文,确保智能体参考的是真实企业数据而非产生幻觉。
图2.具有离线索引和在线检索的多模态RAG管道。
llama-nemotron-embed-vl-1b-v2模型支持三种输入模式——纯文本、纯图像和图像与文本的组合,让您能够对从纯文本文档到幻灯片和技术图表的各种内容进行索引。在本教程中,我们将嵌入一个同时包含图像和文本的示例。该嵌入模型通过Transformers加载,并启用flash attention:
from transformers import AutoModel
model = AutoModel.from_pretrained(
"nvidia/llama-nemotron-embed-vl-1b-v2",
trust_remote_code=True,
device_map="auto"
).eval()
# Embed queries and documents
query_embedding = model.encode_queries(["How does AI improve robotics?"])
doc_embeddings = model.encode_documents(texts=documents)
在初始检索后,llama-nemotron-rerank-vl-1b-v2模型会结合文本和图像对结果进行重新排序,以确保检索后的准确性更高。在基准测试中,添加重排序可将准确率提高约6-7%,这在精度要求较高的场景中是一项显著的提升。
步骤3:使用NemotronSpeech ASR添加实时语音功能
锚定完成后,下一步是通过语音实现自然交互。
图3.基于NVIDIANemotronSpeech ASR的ASR管道
Nemotron Speech ASR是一个流式模型,基于Granary数据集中数万小时的英语音频及多种公开语音语料库进行训练,同时经过优化实现超低延迟的实时解码。开发者将音频流式传输到ASR服务,在收到文本结果后,将输出直接输入到RAG管道中。
import nemo.collections.asr as nemo_asr
model = nemo_asr.models.ASRModel.from_pretrained(
"nvidia/nemotron-speech-streaming-en-0.6b"
)
transcription = model.transcribe(["audio.wav"])[0]
该模型具备可配置的延迟设置,在80毫秒的最低延迟设置下,平均字词错误率(Word Error Rate, WER)为8.53%,延迟为1.1秒时,WER进一步降低至7.16%,这一表现显著低于语音助手、现场工具和免提工作流所要求的一秒关键阈值。
步骤4:使用Nemotron内容安全和PII模型强制执行安全措施
跨地区和跨语言运行的AI智能体不仅必须理解有害内容,还必须理解文化细微差别和上下文相关的含义。
图4.使用NVIDIA LlamaNemotronSafety Guard模型的安全管道,检测安全或不安全内容。
llama-3.1-nemotron-safety-guard-8b-v3模型可提供20多种语言的多语言内容安全,并可对23个安全类别进行实时PII检测。
该模型通过NVIDIA API提供,无需额外托管基础设施,即可轻松添加输入和输出过滤。它可以基于语言、方言和文化背景区分含义不同但表达相似的短语,这在处理可能受到干扰或非正式的实时ASR输出时尤为重要。
from langchain_nvidia_ai_endpoints import ChatNVIDIA
safety_guard = ChatNVIDIA(model="nvidia/llama-3.1-nemotron-safety-guard-8b-v3")
result = safety_guard.invoke([
{"role": "user", "content": query},
{"role": "assistant", "content": response}
])
步骤5:使用Nemotron3 Nano添加长上下文推理功能
NVIDIANemotron3 Nano为智能体提供推理能力,结合了高效的混合专家(MoE)机制和混合Mamba-Transformer架构,支持1M token上下文窗口。这使得模型能够在单个推理请求中合并检索到的文档、用户历史记录和中间步骤。
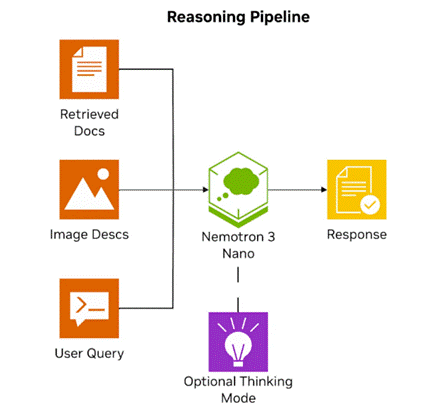
图5.使用NVIDIANemotron3 Nano的推理管道。
当检索到的文档包含图像时,智能体首先使用NemotronNano VL来描述这些图像,然后将所有信息传递给Nemotron3 Nano以获得最终的响应。该模型支持可选的思考模式,可用于更复杂的推理任务:
completion = client.chat.completions.create(
model="nvidia/nemotron-3-nano-30b-a3b",
messages=[{"role": "user", "content": prompt}],
extra_body={"chat_template_kwargs": {"enable_thinking": True}}
)
输出在返回之前会通过安全过滤器,将您的检索增强型查找转换为具有完整推理能力的智能体。
步骤6:使用LangGraph将所有内容连接起来
LangGraph将整个工作流编排为一个有向图。每个节点处理一个阶段,即转录、检索、图像描述、生成和安全检查,组件之间有清晰的切换:
VoiceInput→ASR→Retrieve→Rerank→DescribeImages→Reason→Safety→Response
智能体状态流经每个节点,并在过程中积累上下文。这种结构简化了添加条件逻辑、重试失败步骤或基于内容类型进行分支。配套Notebook中的完整实现展示了如何定义每个节点,并将其连接到生产就绪型管道中。
步骤7:部署智能体
智能体能够在本地机器上稳定运行后,您就可以将其部署到任意位置。在需要分布式摄取、嵌入生成或大规模批量向量索引时,可使用NVIDIA DGX Spark。Nemotron模型可以进行优化、打包并作为NVIDIANIM运行(一套预构建的GPU加速推理微服务,专为在NVIDIA基础设施上部署AI模型而设计),并可直接从Spark调用以进行可扩展的处理。当您需要按需的GPU工作空间且无需系统设置直接运行Notebook,同时还希望获得可与团队轻松共享的Spark集群远程访问时,可以选择使用NVIDIA Brev。
如果您想查看适用于物理机器人助手的相同部署模式,请查看基于Nemotron和DGX Spark的ReachyMini个人助理教程。
两个环境都使用相同的代码路径,因此您可以由实验阶段平稳过渡到生产环境,所需的修改极少。
您所构建的内容
现在,您拥有一个由Nemotron驱动的智能体核心结构,该结构由四个核心组件组成:用于语音交互的语音ASR、用于实现信息真实性的多模态RAG、考虑文化差异的多语言内容安全过滤,以及用于长上下文推理的Nemotron3 Nano。相同的代码适用于本地开发到生产级GPU集群运行。
| 组件 | 目的 |
| 多模态RAG | 在真实的企业数据中锚定响应 |
| 语音ASR | 实现自然语音交互 |
| 安全 | 跨语言和文化背景识别不安全内容 |
| 长上下文LLM | 通过推理生成准确的响应 |
表2.用于构建基于Nemotron的语音智能体的四个组件概览——多模态RAG、语音ASR、多语言内容安全和长上下文推理。
本教程中的每个部分都与Notebook中的相应部分直接对应,因此您可以逐步实施和测试该流程。一旦端到端工作正常,相同的代码即可扩展到生产部署。
关于作者
Chris Alexiuk 是 NVIDIA 的深度学习开发者倡导者,负责创建技术资源,帮助开发者使用 NVIDIA 提供的一整套强大 AI 工具。Chris 拥有机器学习和数据科学背景,对大型语言模型的一切充满热情。
Isabel Hulseman 是 NVIDIA 的综合营销经理,专注于人工智能软件。她的兴趣领域包括用于构建、定制和部署大型语言模型和生成人工智能应用程序的加速推理和解决方案。
- 随机文章
- 热门文章
- 热评文章
- 全国电影(广州)交易会暨第25届全国优秀影片推介会盛大召开
- 国家医保局官微刊文反驳DRG致医院亏损,评论区激辩获网友点赞
- 夜读丨一抹精致,无用而美丽
- 恒丰银行扎实开展全民国家安全教育日活动
- 2024年世界少年儿童发展论坛开幕
- 刘彦春、李晓星、赵蓓,一季度最新调仓情况曝光!
- 受下游铁水产量回升带动 双焦氛围改善
- 核污染水排海引全球关注 日本民众担忧未来隐患
- 个人养老金制度落地两周年:开户营销战持续 投资者缴存热情淡
- 证监会党委理论学习中心组在《人民日报》发文表示 增强资本市场制度包容性 依法全面加强监管
- 涉嫌试图推翻2020年美总统竞选结果 多人受重罪指控
- 关于近期加强监管、防范风险情况的答记者问
- 商务部:西方有关中国“产能过剩”的炒作毫无道理 中方坚决反对
- 1“赛事+”提升城市“流量” 陕西商洛拓经济发展新“赛道”
- 2“五一”临近 持基过节的投资者要注意这几点
- 3华发股份:成功入选“人民优选”品牌 五一黄金周热销30亿
- 4钟鼓楼老街区的古都新事
- 5到2027年产业规模达到2000亿元 浙江发布历史经典产业高质量发展计划
- 6非常危险!女子摔成粉碎性骨折!又是因为洞洞鞋,夏天多人中招……
- 7金税四期试点上线,财税体制改革拉开帷幕!或有资金借道信创ETF基金(562030)逢跌进场布局
- 8IDC:24Q1全球PC出货量恢复增长 达到疫情前水平
- 9初步数据:我国一季度经常账户顺差392亿美元
- 10“发现山西之美”TDC旅游发现者大会举办:共话文旅新生态 邀客体验新玩法
- 11国门“夫妻档” 国庆共坚守
- 12北交所一周审核动态:2家企业更新进展 胜业电气二轮问询回复中称家电头部客户对价格敏感度较低
- 13甘肃白银县域经济:从“一枝独秀”到“多点开花”
- 1大裁员下,特斯拉两名顶级高管离职
- 2奇瑞将与欧洲高端品牌签署技术平台授权协议
- 32024中国长三角青年企业家交流大会在杭州举办
- 4雷克萨斯GX中东版 全部在售 2023款 2022款 2020款 2019款 2018款成都远卓名车雷克萨斯GX中东版团购钜惠20万 欢迎上门试驾
- 5零跑C16将搭载中创新航磷酸铁锂电池
- 6Q1净利微增7%,宁德时代股东总数较2023年年末减少10728户
- 7哪吒,需要背水一战
- 8“新”中有“机”!创新服务承接新流量 撬动消费升级
- 9非创始版SU7何时交付 小米:工厂生产爬坡 全力提高产能
- 10央媒评卧铺挂帘:谁买的票谁做主
- 11江西南昌首部“多规合一”国土空间总体规划获批
- 12方程豹旗舰硬派越野!豹8正式亮相:仰望U8“青春版”登场
- 13583家族/造型霸气 方程豹豹8量产版发布












