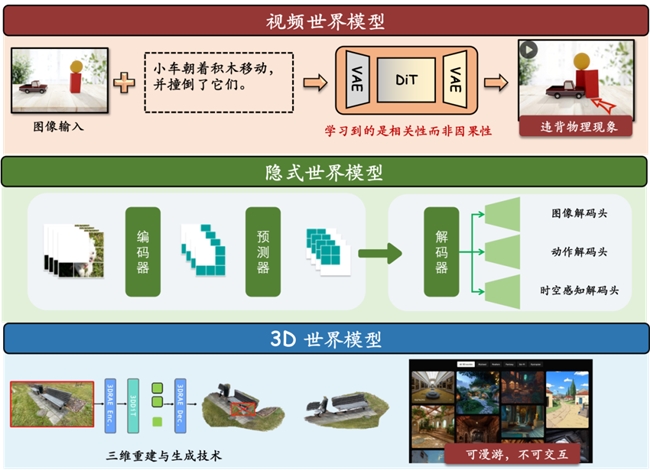
01【ACL-2026】BWLA:面向LLMs的1-bit权重与低比特激活后训练量化框架

后摩智能芯片算法团队提出BWLA(Binarized Weights and Low-bit Activations),这是首个在无需重训练的后训练量化框架下,同时实现1-bit权重与低比特激活(如6-bit)的大语言模型压缩方法。现有二值化方法虽然能够将权重压缩到接近1bit,但大多无法有效处理激活中的重尾离群值,因此仍需保留高精度激活,推理时还需要进行权重反量化,难以真正实现端到端加速。BWLA从权重与激活的统计分布出发,通过联合重塑权重分布与抑制激活离群值,显著提升了W1AX场景下的量化精度与部署效率。
随着 LLMs 参数规模持续扩大,模型推理对显存、带宽和计算资源的需求不断上升,极大限制了其在端侧设备、嵌入式系统和边缘计算平台中的部署。二值化是最具潜力的极限压缩方案之一,可将权重存储降低到1bit,从根本上减少模型存储与访存开销。然而,LLM的权重通常呈现单峰、近似高斯分布,与 {-1, +1} 二值码本天然不匹配,直接二值化会引入严重误差;同时,激活分布存在显著重尾与极端离群值,在低比特量化时会造成严重数值失真。这两个问题使得已有方法难以在保持模型精度的同时实现真正的W1AX量化。
BWLA以“权重双峰化、激活去离群、低开销部署”为核心目标,构建了一个无需微调、面向端侧推理友好的统一后训练量化框架,主要包含两大核心创新:
核心创新一:正交Kronecker变换(Orthogonal-Kronecker Transformation, OKT)。OKT通过学习严格正交的Kronecker结构变换,将原本单峰的权重分布显式重塑为更适合二值码本的对称双峰分布,从而降低权重二值化误差。与普通稠密正交矩阵相比,OKT将大矩阵分解为两个小型正交矩阵的Kronecker积,在保持正交可逆性的同时,大幅降低计算与存储开销。由于正交变换满足逆矩阵等于转置矩阵,OKT可以在保持前向计算等价性的前提下作用于激活空间,有效打散激活相干性并抑制重尾离群值,为低比特激活量化创造更稳定的数值条件。
核心创新二:近端SVD投影(Proximal SVD Projection, PSP)。在OKT 完成全局分布对齐后,仍可能存在部分结构化残差不利于二值化。PSP进一步引入轻量级低秩残差修正,通过近端优化与截断SVD投影吸收残余离群成分,使变换后的权重分布更加接近对称双峰结构。该模块仅带来极小的额外参数开销,却能进一步增强权重量化可分性与模型稳定性,与OKT形成互补:OKT负责全局分布重塑与激活平滑,PSP负责局部残差校正与量化误差细化补偿。
实验表明,BWLA在多个主流LLM家族上均显著优于现有二值化与低比特量化方法。在Qwen3-32B上,BWLA在6-bit激活量化下的WikiText2困惑度达到11.92,显著优于现有SOTA方法约38的结果;在五个zero-shot任务上,BWLA相比已有方法带来超过70%的性能提升,并实现3.26×的推理加速,展示出强大的实际部署潜力。相比W4A4量化方法,BWLA也能取得更高吞吐,体现出1-bit权重在访存受限推理场景中的突出优势。
总体而言,BWLA首次在纯后训练量化框架下打通了1-bit权重 + 低比特激活的高精度压缩路径,解决了传统二值化方法无法处理激活重尾、难以端到端加速的核心难题。该方法为LLMs在车载、嵌入式、移动终端和边缘设备等资源受限场景中的高效部署提供了关键技术支撑,也进一步完善了后摩智能在端侧AI 芯片与大模型压缩算法协同优化方向的技术布局。
文章链接:https://arxiv.org/abs/2605.00422
02【ICML-2026】TWLA:突破W1.58A4后训练量化瓶颈,推动三值化大模型迈向端侧高效推理
继在大模型压缩、低比特量化与端侧部署方向持续取得突破后,后摩智能芯片算法团队进一步提出TWLA(Ternarized Weights and Low-bit Activations),面向大语言模型在资源受限场景中的高效部署需求,系统解决三值化权重与低比特激活联合量化中的精度坍塌问题。该方法在无需重训练的后训练量化框架下,实现1.58-bit权重压缩与4-bit激活量化,在显著降低模型存储与推理成本的同时,保持了强大的模型精度与任务泛化能力。
随着大语言模型参数规模不断增长,模型推理对显存容量、访存带宽和计算资源提出了极高要求。三值化作为一种极具潜力的极低比特压缩技术,将权重约束到{-1, 0, +1},相比二值化具备更强的表达能力,同时仍能显著减少乘法计算和模型存储开销。然而,现有三值化方法大多停留在权重量化层面,通常保留高精度激活以避免精度损失,导致推理过程中仍需进行权重反量化,难以真正释放低比特计算带来的端到端加速潜力。更具挑战的是,在W1.58A4这一极限压缩配置下,大模型同时面临三类关键瓶颈:第一,预训练权重通常呈单峰近高斯分布,与三值码本天然不匹配,直接三值化会造成较大投影误差;第二,激活分布存在显著重尾和极端离群值,4-bit激活量化极易引发数值失真;第三,不同层在低比特激活量化下的敏感性差异明显,少数“薄弱层”可能触发误差级联,导致整体性能快速下降。TWLA正是围绕这些问题构建了一个完整的三值权重与低比特激活协同优化框架。
TWLA以“精准三值化、分布重塑、层间协同分配”为核心思路,设计了三个相互配合的关键模块:
核心创新一:欧氏到流形的非对称三值量化器(E2M-ATQ)。针对预训练权重存在非零均值、直接对称三值化难以准确拟合的问题,TWLA提出 Euclidean-to-Manifold Asymmetric Ternary Quantizer。该模块首先在欧氏权重空间中进行稳定初始化,获得可靠的三值模式;随后固定三值结构,在由校准激活二阶统计量定义的度量空间中重新定位行级偏移与缩放参数,使量化权重不仅在数值上接近原始权重,更能在层输出层面对齐浮点模型。相比单纯最小化权重重构误差,E2M-ATQ更关注实际前向输出误差,从而显著提升三值化后的可校准性和模型稳定性。
核心创新二:Kronecker正交三峰分布塑形(KOTMS)。为了从根源上缓解权重分布与三值码本之间的不匹配,TWLA进一步提出Kronecker Orthogonal Tri-Modal Shaping。KOTMS通过轻量级Kronecker结构正交变换,将原本单峰的权重分布重塑为更适合{-1, 0, +1}三值码本的对称三峰分布,使权重在量化前就具备更好的三值可分性。与直接学习大规模辅助矩阵不同,KOTMS将正交矩阵拆解为两个小型Kronecker因子,在保持严格可逆和前向等价的同时,大幅降低额外计算与存储开销。同时,该正交变换也会对激活进行共享混合,从统计上削弱激活相干性与重尾离群值,为4-bit激活量化提供更平滑的动态范围。
核心创新三:层间感知激活混合精度分配(ILA-AMP)。与传统混合精度量化方法不同,TWLA并不简单地将每一层视为独立对象,而是显式建模相邻层之间的误差传播。由于激活量化会改变当前层输出分布,并进一步影响下一层输入统计,低比特量化误差往往具有明显的层间耦合效应。ILA-AMP将单层敏感性损失与相邻层二阶交互损失统一到一个动态规划友好的目标函数中,在全局比特预算约束下,为不同层分配合适的激活精度。该设计能够识别并保护对 4-bit激活量化更敏感的关键层,避免少数薄弱层引发全模型性能坍塌。
实验结果表明,TWLA在LLaMA与Qwen3系列模型上均显著优于现有2-bit 和 sub-2-bit后训练量化方法。在A16设置下,TWLA以更低的1.58-bit权重精度取得了优于GPTQ、QuaRot、SliM-LLM、PB-LLM和PT2-LLM的性能。例如在LLaMA3-8B上,TWLA将seven zero-shot平均准确率提升至62.98%,同时将WikiText2困惑度降低至9.39,相比PT2-LLM展现出明显优势。在更具挑战性的W1.58A4设置下,已有方法普遍出现困惑度爆炸和任务精度坍塌,而TWLA仍能保持稳定表现。以LLaMA2-70B为例,TWLA在4-bit激活量化下达到71.10%的seven zero-shot平均准确率,超过FP16模型性能的92%,同时显著降低模型内存开销。相比同样关注激活混合精度的ResQ,TWLA在精度和压缩率上均展现出更强的综合优势。
总体来看,TWLA将三值化大模型从“权重压缩”进一步推进到“权重—激活联合低比特推理”的新阶段。通过E2M-ATQ提升三值参数校准能力,通过KOTMS 重塑权重与激活分布,通过ILA-AMP控制低比特激活下的层间误差传播,TWLA在W1.58A4这一极具挑战性的配置下实现了高精度、低内存与高吞吐的统一。该成果为大语言模型在车载、边缘设备、嵌入式终端和隐私敏感型本地推理场景中的规模化部署提供了关键技术支撑,也进一步丰富了后摩智能在端侧 AI 芯片与低比特算法协同设计方向的技术体系。
文章链接:https://icml.cc/virtual/2026/poster/61264
03【ICML-2026】DLLMQuant:面向扩散大语言模型的专属后训练量化框架
继在低比特量化与端侧部署方向持续突破后,后摩智能芯片算法团队进一步提出DLLMQuant,面向基于扩散的大语言模型(DLLM)的独特生成机制,系统性解决传统后训练量化(PTQ)方法在该类模型上精度坍塌的问题,实现高效、无损的模型压缩与推理加速。
随着大语言模型技术的演进,扩散式大语言模型(DLLM)凭借其非自回归并行生成的优势,在文本生成、代码补全与复杂推理任务中展现出巨大潜力。然而,其庞大的模型规模、高昂的推理成本,以及迭代生成过程中独特的动态掩码机制,为其规模化部署带来了严峻挑战。后训练量化(PTQ)作为大模型部署的关键技术,在标准自回归大模型上已被证明行之有效,但直接应用于DLLM时,会出现严重的精度损失,例如在W4A4配置下,AWQ、GPTQ等主流方法在LLADA模型上的精度暴跌超过16%,甚至引发困惑度爆炸。
深入分析发现,传统PTQ方法失效的根源,在于其设计与DLLM的核心特性存在三重不匹配:DLLM的生成过程是多步迭代的,不同解码步的令牌掩码比例和激活分布持续变化,静态的校准数据无法覆盖完整的分布空间;量化误差并非一次性的,而是会随着迭代解码过程不断放大,形成级联效应,导致模型性能随解码步数增加持续恶化;模型中同时存在已解掩码的确定性令牌与待预测的掩码令牌,特征分布呈现多峰、混杂状态,不适用于常规的PTQ误差优化策略。这些不匹配共同导致现有量化方案难以适配DLLM的运行机理,进而出现显著的精度下降。
DLLMQuant正是围绕这些核心痛点,构建了一套完整的、专为DLLM设计的量化优化框架。
核心创新一:时间-掩码自适应采样(TMAS)。针对DLLM在不同解码步与掩码比例下的分布漂移问题,DLLMQuant提出了Temporal-Mask Adaptive Sampling (TMAS)。该方法打破了传统校准数据静态采样的局限,设计了一种兼顾时间步与掩码比例的动态校准策略。通过在不同解码阶段、不同掩码比例下采集校准数据,构建覆盖完整生成过程的动态分布图谱,使量化器能够精准捕捉模型在整个推理流程中的统计特征,为后续的权重与激活量化提供可靠的分布依据。
核心创新二:交互感知激活量化(IA-AQ)。为了从根源上抑制量化误差在迭代生成中的累积与传播,DLLMQuant提出了Interaction-Aware Activation Quantization (IA-AQ)。该模块聚焦于DLLM中误差最敏感的注意力机制,通过分析注意力权重与令牌交互模式,识别出对最终结果影响最大的关键令牌区域。在激活量化过程中,对这些关键区域施加更严格的误差约束,优先降低其量化噪声,从而打破误差传播链,避免少数薄弱层引发全模型性能坍塌。
核心创新三:确定性引导量化(CGQ)。针对DLLM中确定性与概率性令牌混杂的分布特性,DLLMQuant提出了Certainty-Guided Quantization (CGQ)。该方法以令牌的掩码状态与置信度为核心,构建了一个动态误差加权机制。对于高置信度的已解码令牌,优先保证其量化精度;对于低置信度的掩码令牌,则在可接受的误差范围内进行压缩。通过这种方式,将有限的比特预算精准分配给最关键的令牌,使量化优化目标与DLLM的生成逻辑深度对齐,显著提升了量化后模型的整体稳定性。
实验结果表明,DLLMQuant在LLaDA、LLADA-1.5与DREAM等主流DLLM 模型上,均显著优于RTN、AWQ、GPTQ与QuaRot等传统量化方法。在极具挑战性的W4A4配置下,DLLMQuant在LLaDA-8B模型的GSM8K数学推理任务上,实现了超过10个百分点的精度提升,同时带来了约1.6倍的推理加速与 3.2倍的内存节省。在涵盖文本生成、代码补全与常识推理的9项基准任务中,DLLMQuant均实现了平均超过2%的性能提升,且在长文本生成任务上展现出更强的稳定性,验证了其方法的通用性与有效性。
总体来看,DLLMQuant将大模型后训练量化技术,从 “自回归模型” 成功拓展到 “扩散式模型” 这一全新领域。通过TMAS、IA-AQ与CGQ三大核心技术,系统性解决了动态分布漂移、误差累积传播与令牌状态混杂三大难题,在4比特极限量化下实现了高精度、低内存与高吞吐的统一。该成果为基于扩散的大语言模型在边缘设备、嵌入式终端与隐私敏感场景中的规模化部署,提供了关键技术支撑,也进一步丰富了后摩智能在端侧AI芯片与低比特算法协同设计方向的技术体系。
文章链接:https://icml.cc/virtual/2026/poster/61264
- 随机文章
- 热门文章
- 热评文章
- 230家医药公司披露年报 超五成实现净利润增长
- 调查:美国青少年VR设备使用率增长,近1/3拥有VR设备
- 追问|味觉异常可能增加脑卒中的患病风险?
- 市政府代表团出访欧洲三国 推动多领域交流合作 共享发展新机遇 同谱合作新篇章
- TMGM每日市场(04月22日)
- 英镑本周料收复近期失地,关注英国PMI和美国PCE
- 习近平会见美国国务卿布林肯
- 紫金银行2023年实现净利润16.19亿元,同比增长1.16% | 财报速递
- 节前打虎,司法部原党组成员、副部长刘志强退休一年后被查
- 中基协:私募证券基金参与DMA业务不得超过2倍杠杆
- 权益型公募布局固收尝到甜头 跟风“照抄作业”恐难如愿
- 时隔近三年,加加食品再遭“ST”,关联方加工损失逾5000万
- 去年保险专业中介机构减少16家
- 1“赛事+”提升城市“流量” 陕西商洛拓经济发展新“赛道”
- 2“五一”临近 持基过节的投资者要注意这几点
- 3华发股份:成功入选“人民优选”品牌 五一黄金周热销30亿
- 4钟鼓楼老街区的古都新事
- 5到2027年产业规模达到2000亿元 浙江发布历史经典产业高质量发展计划
- 6非常危险!女子摔成粉碎性骨折!又是因为洞洞鞋,夏天多人中招……
- 7金税四期试点上线,财税体制改革拉开帷幕!或有资金借道信创ETF基金(562030)逢跌进场布局
- 8IDC:24Q1全球PC出货量恢复增长 达到疫情前水平
- 9初步数据:我国一季度经常账户顺差392亿美元
- 10“发现山西之美”TDC旅游发现者大会举办:共话文旅新生态 邀客体验新玩法
- 11国门“夫妻档” 国庆共坚守
- 12北交所一周审核动态:2家企业更新进展 胜业电气二轮问询回复中称家电头部客户对价格敏感度较低
- 13(中国新貌)“国宝”大熊猫:栖居更美境 云游更广天
- 1大裁员下,特斯拉两名顶级高管离职
- 2奇瑞将与欧洲高端品牌签署技术平台授权协议
- 32024中国长三角青年企业家交流大会在杭州举办
- 4雷克萨斯GX中东版 全部在售 2023款 2022款 2020款 2019款 2018款成都远卓名车雷克萨斯GX中东版团购钜惠20万 欢迎上门试驾
- 5零跑C16将搭载中创新航磷酸铁锂电池
- 6Q1净利微增7%,宁德时代股东总数较2023年年末减少10728户
- 7哪吒,需要背水一战
- 8“新”中有“机”!创新服务承接新流量 撬动消费升级
- 9非创始版SU7何时交付 小米:工厂生产爬坡 全力提高产能
- 10央媒评卧铺挂帘:谁买的票谁做主
- 11江西南昌首部“多规合一”国土空间总体规划获批
- 12方程豹旗舰硬派越野!豹8正式亮相:仰望U8“青春版”登场
- 13583家族/造型霸气 方程豹豹8量产版发布