[首发于智驾最前沿微信公众号]在自动驾驶领域,如何准确地感知和理解周围的三维环境始终是技术核心。早期的感知方案主要依赖于二维目标检测,即通过图像识别出车辆、行人和交通标志,并在其周围画出矩形框。
这种基于框的识别方式在面对复杂和不规则物体时显得力不从心。随着技术的发展,鸟瞰图技术将多摄像头采集的图像转换到俯视坐标系中,极大地改善了路径规划的效率,但它依然忽略了高度维度的信息。占用网络的出现彻底改变了这一现状。

占用网络的优势是什么?
占用网络不再只是关注路面上“这是一个什么物体”,而是通过将三维空间切分为无数个细小的方块,即体素,来预测每个空间单位是否被占据。这种从“物体优先”向“几何优先”的转变,使自动驾驶系统能够识别出那些在传统模型库中不存在的异形物体,从而有效填补了感知上的语义裂隙。
占用网络的核心优势在于它能够提供一种密集的、具有高度信息的环境描述。通过这种方式,车辆不仅能看到前方有一辆车,还能感知到路面上的细微起伏、伸向道路的树枝或是倾斜的路灯杆。这种全方位的感知能力直接提升了自动驾驶系统在复杂城市场景和非结构化道路中的安全性。
图片源自:网络
在占用网络的构建过程中,针对不同性质的场景元素采取差异化的处理手段是提升精度的关键。尤其是路面与天空这两类特征迥异的场景,它们分别代表了物理世界的“支撑面”与“无穷远边界”,其处理逻辑在算法底层有着本质的区别。
占用网络通常由一个强大的主干网络提取多视角图像特征,随后利用注意力机制将这些二维特征投影到三维体素空间中。在这一过程中,算法必须能够辨别哪些像素对应着立体的物理障碍物,哪些像素仅仅是作为背景存在。
路面作为车辆行驶的基础,其几何特征的重构精度直接影响到避障和悬挂控制;而天空则是一个没有深度信息的区域,它在占用网络中更多地扮演着“几何定标”和“负约束”的角色。对这两个场景进行差异化处理,不仅是提升算力效率的需要,更是实现高可靠感知的必然选择。

占用网络如何处理路面?
路面在占用网络中被视为最基础的静态场景。虽然在视觉上路面呈现出较为统一的纹理,但在三维空间中,路面的处理远比看上去复杂。路面不仅是“被占据”的体素,它还承载着坡度、颠簸以及路缘石等关键几何信息。
为了做好路面的区分,占用网络首先需要解决高精度的高度估计问题。传统的视觉感知算法在处理远距离路面时,由于透视效应和图像分辨率的限制,会出现严重的深度误差。占用网络通过引入高程重构技术,能够刻画出路面的凹凸不平,这对于车辆在复杂地形下的速度规划至关重要。
在处理路面时,算法会利用“地平面先验”作为约束。这意味着模型会预先假设路面是一个大致连续的表面,并在此基础上通过多帧图像的融合来消除单帧预测带来的噪声。
对于非结构化道路中的起伏,一些先进的模型采用了坡度感知的自适应特征提取模块。该模块可以根据输入图像动态调整特征权重,从而在陡坡或急弯处保持稳定的路面追踪能力。
与处理障碍物不同,路面的体素填充逻辑一般是分层进行的。模型会先生成一个粗略的地面网格,再根据局部的图像特征进行亚体素级别的细节修正,这种从粗到精的过程保证了感知系统对行驶路径的精准判断。
数据层面的处理同样体现了路面的特殊性。在生成用于训练占用网络的地面真值标签时,直接使用激光雷达点云会遇到稀疏性的问题。由于激光束与地面夹角很小,远处的点云几乎无法覆盖地面。
因此,有技术提出了专门的标签生成管线,通过融合多帧序列、利用泊松重构等算法填补空洞,从而生成一个连续、平滑且具有真实语义的路面体素模型。
此外,针对路面反光或阴影导致的识别错误,占用网络会结合语义分割信息,将标记为“可行驶区域”的像素点与空间中的深度值进行交叉验证,确保被占据的路面体素不会与空中的悬浮物混淆。
特斯拉等车企的占用网络通过预测“带符号距离场”来进一步提升路面的表现。这种方法不仅能确定路面是否被占据,还能计算出空间中任意一点距离路面表面的精确距离。这种精度的提升使得车辆能够识别出路面上微小的凸起。这种对路面的精细化建模,极大地增强了自动驾驶系统对复杂路况的适应性。
占用网络如何处理天空?
相比于路面的“重几何”属性,天空在占用网络中的处理逻辑则更倾向于“重语义”和“负反馈”。天空其实是无尽的背景,激光雷达等主动传感器无法在天空区域获得反射信号,因此天空在传感器的原始数据中通常表现为“丢失”或“无穷远”。
如果算法不对天空进行特殊处理,那么在将图像特征投影到三维空间时,天空区域的像素特征可能会因为缺乏深度约束而沿着光束方向发生“漂移”,错误地填充到近处的体素中,形成“深度流血”现象。
为了有效地区分天空,占用网络引入了“天空接地”技术。这一技术是利用大模型或预训练的语义网络识别出图像中的天空区域,并将其作为感知系统的边界约束。
在投影过程中,属于天空区域的体素会被强制标记为“空闲”或“未观测”,从而防止系统在半空中产生虚假的障碍物。这种方法本质上是将天空视为一个过滤器,利用视觉背景的确定性来反向优化三维空间的几何结构。这与路面处理中不断寻找“支撑点”的逻辑正好相反,天空的处理是在不断地进行“空间排除”。
天空在环境理解中还承担着辅助定标的任务。通过分析天空中云层的分布、光线的明暗以及地平线的位置,算法可以辅助修正相机的外参。在无人船或极端地形下的自动驾驶中,利用颜色空间模型(如亮度与饱和度分布)对天空进行精准检测,能够帮助系统更快速地识别出陆地和水面的界限。
在占用网络的训练阶段,对于天空标签的缺失,研究人员会引入“能见度掩码”的机制。该机制能够区分一个体素是确实没有被占据,还是因为被遮挡而无法观测。由于天空永远不会被“占据”,它在能见度推理中提供了一个天然的终点参考。
三透视视图(TPV)等新型表征方式对天空的处理更加得心应手。TPV将空间分解为顶视、侧视和前视三个互相垂直的平面,天空的语义特征可以在侧视和前视图中得到充分的表达,而不会像传统的鸟瞰图(BEV)那样将高度信息完全压缩。
这种多维度的特征融合,当像素出现在图像上方且呈现出天空特有的色彩分布时,其对应的三维体素应具有极低的占据概率。这种语义驱动的几何推理,是占用网络能够处理各种复杂气象和光照条件的关键所在。

异构场景的统一建模与技术协同
占用网络之所以强大,是因为它能在同一个框架下,利用完全不同的逻辑同时处理路面、天空和各种复杂的障碍物。这种统一性是通过复杂的特征提升与融合机制实现的。
在自动驾驶算法中,三透视视图(TPV)和Transformer结构的引入,使得模型能够根据空间位置的动态变化,自适应地应用不同的处理策略。如当系统识别到一个体素位于车辆下方且语义接近“路面”时,会更侧重于几何表面的平滑性;而当体素位于视野上方且呈现天空特征时,系统则会应用更强的负约束来清空该区域。
为了在有限的算力下实现这种精细化的场景区分,有技术提出了“距离感知”的感知范式。在车辆附近的“安全核心区”,系统会分配更高的分辨率和更多的体素单元,以便精确重构路面的每一个细节;而在远距离区域,则采用更粗糙的体素划分,主要依靠语义信息来判断天空和背景的边界。
这种资源分配策略不仅模拟了人类视觉“近精远粗”的特点,还显著提升了系统的实时处理能力。
同时,为了解决传感器数据的稀疏性和噪声问题,自监督学习技术开始崭露头角。通过利用神经辐射场(NeRF)等渲染技术,模型可以将预测的三维占用图重新投影回二维图像,并与原始视频帧进行比对,从而在没有人工标注的情况下,自主学习如何区分复杂的路面纹理与变幻莫测的天空背景。
- 随机文章
- 热门文章
- 热评文章
- 4月10日将迎“龙年龙月龙日龙时”
- Vision Pro用户称佩戴后出现健康问题:头痛、黑眼圈、颈部酸痛
- 韩国计划到 2027 年在 AI 半导体领域投资 9.4 万亿韩元,目标成为 AI 技术三强
- 佩戴分享:欧米茄全新超霸专业月球表白盘款
- 投资者惊呼!这几国要联手干预汇市?后市展望如何?
- 蓝厅观察丨菲律宾威胁提起新一轮仲裁 胡搅蛮缠 毫无意义
- 马棕油期货:地缘政治风险与需求潜力交错,价格何去何从?
- 站稳普惠定位 助力健康中国――中国人寿寿险公司政策性健康险的十年探索
- 以色列引汇市波动,鲍威尔继续影响市场!下周哪些央行可能干预市场?
- 核污染水排海引全球关注 日本民众担忧未来隐患
- 新闻多一点|民主村的城市更新样本
- 故宫:“五一”假期未成年人团队可快速预约、检票
- MH迈汇:黄金作为对冲通胀和违约风险的"好钱"
- 1“赛事+”提升城市“流量” 陕西商洛拓经济发展新“赛道”
- 2“五一”临近 持基过节的投资者要注意这几点
- 3华发股份:成功入选“人民优选”品牌 五一黄金周热销30亿
- 4钟鼓楼老街区的古都新事
- 5到2027年产业规模达到2000亿元 浙江发布历史经典产业高质量发展计划
- 6非常危险!女子摔成粉碎性骨折!又是因为洞洞鞋,夏天多人中招……
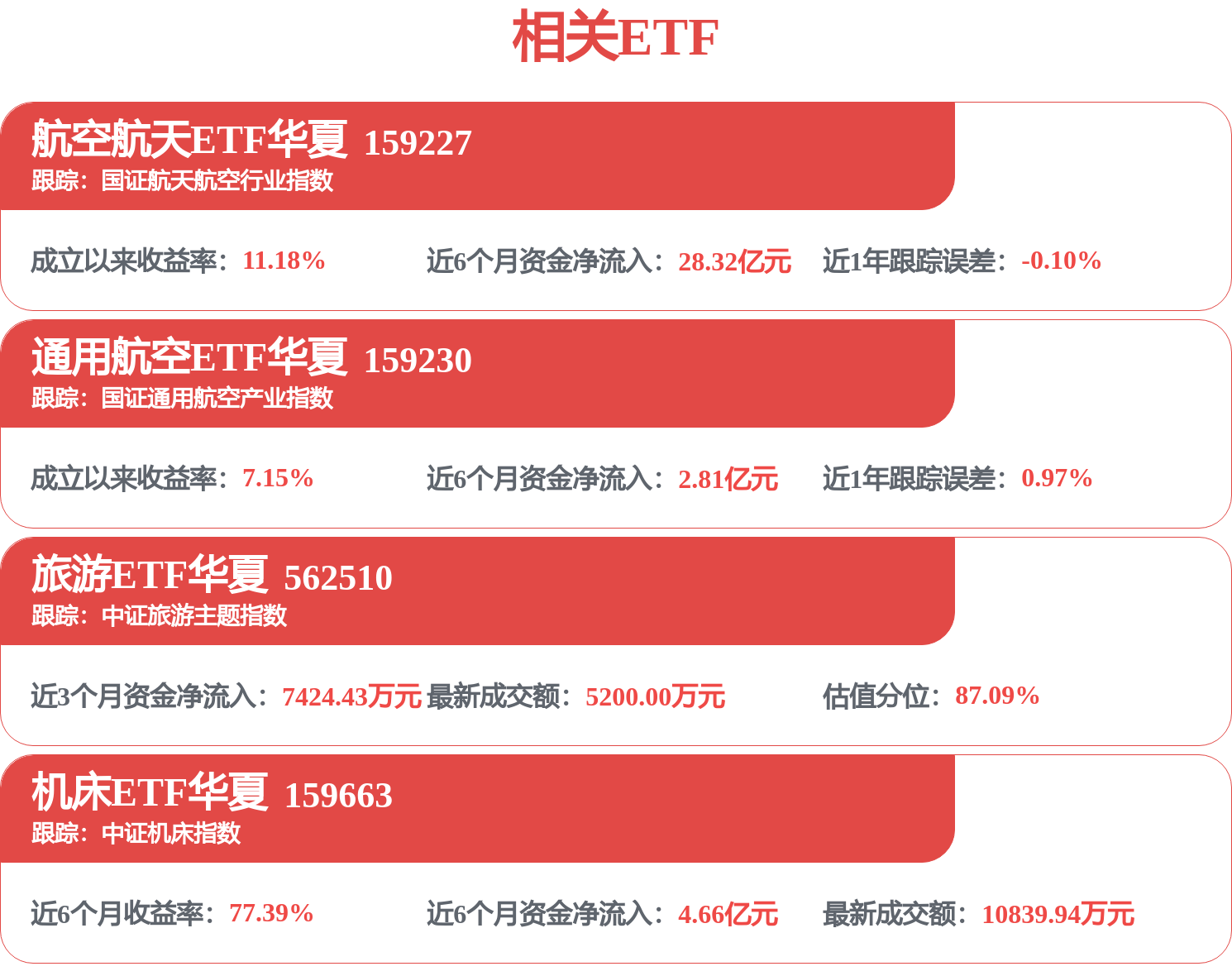
- 7金税四期试点上线,财税体制改革拉开帷幕!或有资金借道信创ETF基金(562030)逢跌进场布局
- 8IDC:24Q1全球PC出货量恢复增长 达到疫情前水平
- 9初步数据:我国一季度经常账户顺差392亿美元
- 10“发现山西之美”TDC旅游发现者大会举办:共话文旅新生态 邀客体验新玩法
- 11国门“夫妻档” 国庆共坚守
- 12北交所一周审核动态:2家企业更新进展 胜业电气二轮问询回复中称家电头部客户对价格敏感度较低
- 13(中国新貌)“国宝”大熊猫:栖居更美境 云游更广天
- 1大裁员下,特斯拉两名顶级高管离职
- 2奇瑞将与欧洲高端品牌签署技术平台授权协议
- 32024中国长三角青年企业家交流大会在杭州举办
- 4雷克萨斯GX中东版 全部在售 2023款 2022款 2020款 2019款 2018款成都远卓名车雷克萨斯GX中东版团购钜惠20万 欢迎上门试驾
- 5零跑C16将搭载中创新航磷酸铁锂电池
- 6Q1净利微增7%,宁德时代股东总数较2023年年末减少10728户
- 7哪吒,需要背水一战
- 8“新”中有“机”!创新服务承接新流量 撬动消费升级
- 9非创始版SU7何时交付 小米:工厂生产爬坡 全力提高产能
- 10央媒评卧铺挂帘:谁买的票谁做主
- 11江西南昌首部“多规合一”国土空间总体规划获批
- 12方程豹旗舰硬派越野!豹8正式亮相:仰望U8“青春版”登场
- 13583家族/造型霸气 方程豹豹8量产版发布